Title sounds a bit nasty eh ?!
I was confronted with this earlier this week, which was only noticed after logging into Unisphere to do some provisioning tasks.
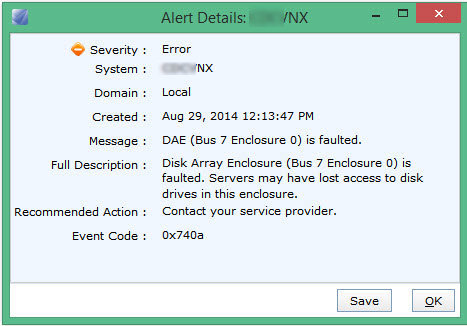
At this point, I had received no alerts (array side) nor any host issues. More alarmingly, no notifications. Oops.
A quick fault check from naviseccli confirmed the alert, but again provided few details;
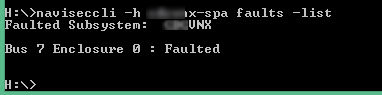
CRU check (Customer Replaceable Unit) showed all parts present, but the particular DAE as just ‘faulted’. Really not particularly helpful at all.
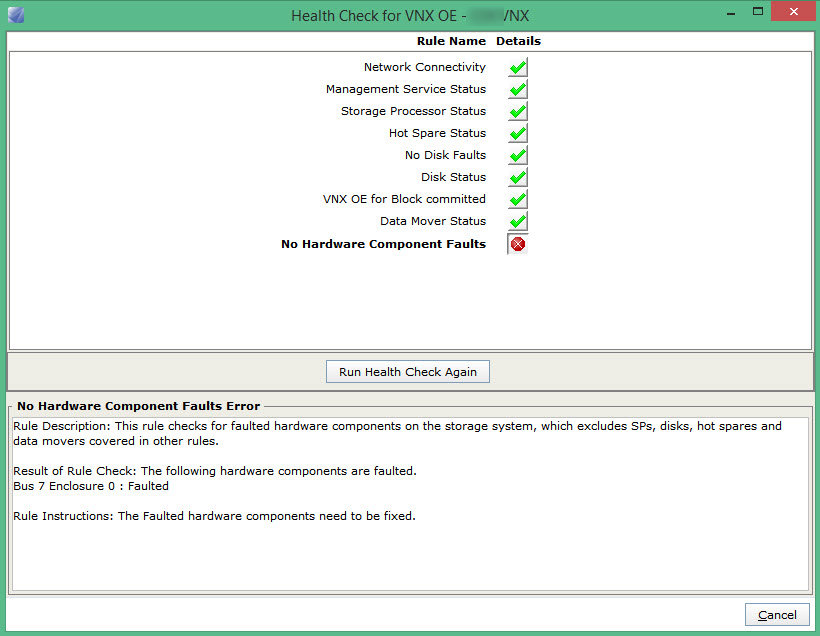
A health check through USM also showed the fault, but NO DETAILS, and the hardware status from the GUI was just as concise.
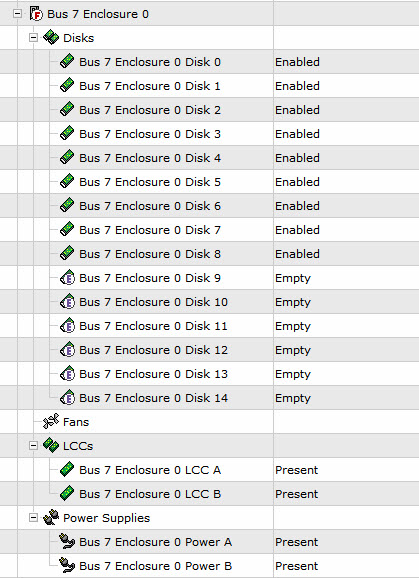
Powerpath V/E (for esxi hosts) and Powerpath (for physical hosts) all showed full path redundancy, and all LUNs were intact and available.
A perfect time to kick off some SP Collects so the forensic exercise can begin. Also opportune time to log an SR too, to get all support options started. As I had all data access, I just logged it as an S3.
Powergrepping through the SP collects (for the string ‘Storage Array Faulted Bus 7 Enclosure 0‘, ) nested in the SPA*sus.zip from the SPA SP Collect. (Sounds like a Matryoshka Doll !) I found this;
08/29/2014 02:11:23 N/A (2580)Storage Array Faulted Bus 7 Enclosure 0 : Faulted
08/29/2014 02:11:44 N/A (712789a3)Enclosure 7_0, LCC 1, changed from OK to Faulted. Fault detail:Expander faulted. Connector 15 faulted. Output cable or LCC should be replaced. Gather SPcollect logs and contact your service provider. 0000040007002c00d3040000a38927e1a38927e10000000000 Flaredrv
Now it’s getting interesting. While I was waiting for contact back from support, I decided I would go and check the cabling status.
The DAE status light was amber. On the DAE side everything looked good. All green, cables seated and clearly looped away. Looking at the SP side however something appeared not quite right.

Where the SAS cable was plugged into the SP, the loop indicator for this BUS (7) was green, whereas for all other DAE’s they were blue. A clear case of “one of these things is not like the others !”.

As per the hardware guide, these LED’s should all be blue to indicate that there is full SAS connectivity and that all lanes on the BUS are operating at 6Gb/s. Now we’re getting somewhere.
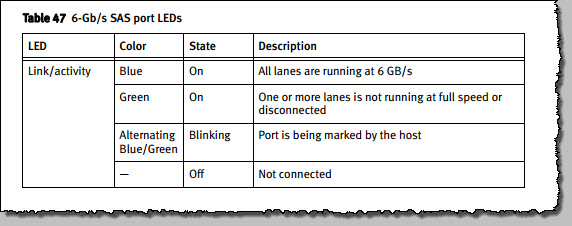
After careful consideration* (and triple-checking all other connectivity) both SAS cable ends were reseated. The loop indicator went blue (within a second) and the fault indicator on the front of the DAE changed from amber to blue.
The alert was gone in Unisphere, and all indicators changed back to normal.


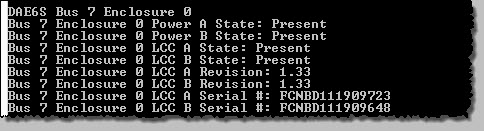
Hurrah ! On with the show
* NOTE: Do NOT attempt to remove/refit/reseat any cables unless you are experienced and know what you are doing. It’s entirely possible to cause a DAE ( and then Storage Pool) or even FastCache to degrade (if the disk are contained vertically across DAE’s). In this case it may be necesary to trespass LUNs and shutdown an SP. Engage support as required and always be cautious when doing these operations.
Degraded DAE’s and FastCache will definitely see you have bad day, and in all likelihood, a long night.
Have you solved this fault?Could you tell me your way?Thank you🙏
Hi, the fix was to reseat the LCC cable at the SP. If this doesn’t work for you it may be the LC cable or actual LCC
it solve my issue
Good to hear 🙂